
Michael Paulson joins Lyle to chat about a better way to transfer data between web servers and clients esp. in a JavaScript environment.
Also some feedback on our GSe50s16 opening discussion about the difference between Programers and Engineers; Alex joins us with some of his thoughts.
This episode we started talking about the differences between Engineer, Programer, Developer.
Alex and others had feedback on that discussion.
This is the motivation for explaining what Flatbuffers are and why they are amazingly cool. So this will be a series of articles that rely as much as possible on data, and little as possible on feelings. You know, practical science shit.
JSON (JavaScript Object Notation) is a lightweight data-interchange format. It is easy for humans to read and write. It is easy for machines to parse and generate. It is based on a subset of the JavaScript Programming Language, Standard ECMA-262 3rd Edition – December 1999. JSON is a text format that is completely language independent but uses conventions that are familiar to programmers of the C-family of languages, including C, C++, C#, Java, JavaScript, Perl, Python, and many others. These properties make JSON an ideal data-interchange language.
JavaScript typed arrays are array-like objects and provide a mechanism for accessing raw binary data. As you may already know, Array objects grow and shrink dynamically and can have any JavaScript value. JavaScript engines perform optimizations so that these arrays are fast. However, as web applications become more and more powerful, adding features such as audio and video manipulation, access to raw data using WebSockets, and so forth, it has become clear that there are times when it would be helpful for JavaScript code to be able to quickly and easily manipulate raw binary data in typed arrays.
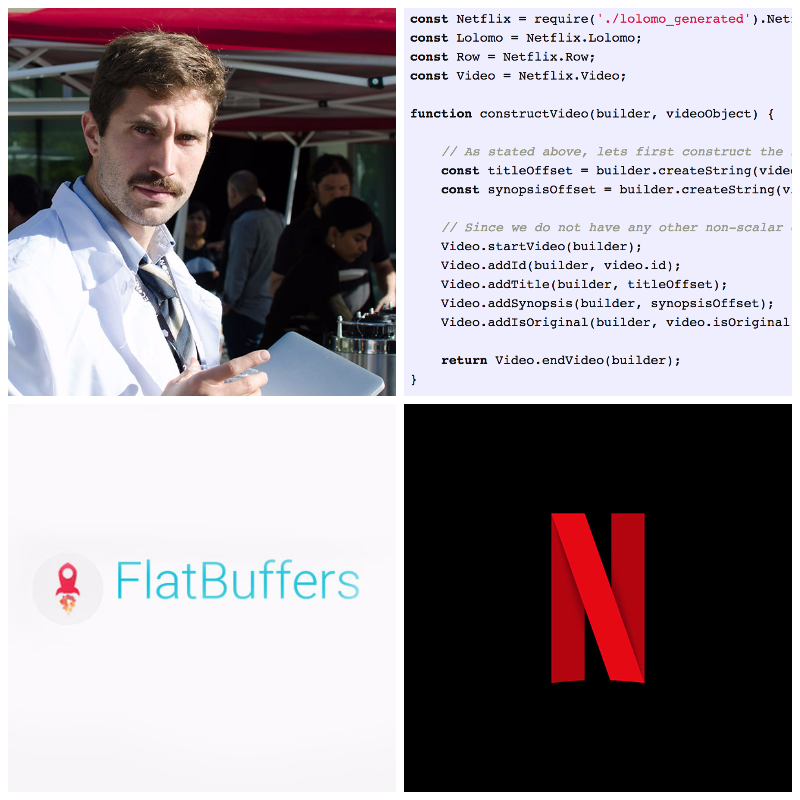
Lets build Netflix! All of the code I
Protocol Buffers is indeed relatively similar to FlatBuffers, with the primary difference being that FlatBuffers does not need a parsing/ unpacking step to a secondary representation before you can access data, often coupled with per-object memory allocation. The code is an order of magnitude bigger, too. Protocol Buffers has neither optional text import/export nor schema language features like unions.
I decided to show a bit about how I record the show, and to thank the Patrons.

e52s16